

Zusammenfassung
In today’s fast-paced business world, milliseconds matter. The NVIDIA AI Data Platform, integrated with FlashBlade//EXA and Portworx, enables organizations to not just accelerate inference but also unlock precision reasoning at scale.


In einer Zeit, in der Millisekunden die Marktführerschaft bestimmen können, stehen Unternehmen vor einer kritischen Herausforderung: riesige Daten-Repositorys mit beispielloser Geschwindigkeit und Genauigkeit in verwertbare Intelligenz umzuwandeln. Unternehmen, Hyperscaler und Neoclouds wie Meta- und Coreweave-Kunden haben mit FlashBlade//S™ und der Pure Storage-Plattform für viele ihrer AIWorkload-Anforderungen einen enormen Erfolg erzielt. Mit mehreren NVIDIA-zertifizierten Storage-Validierungen können Kunden darauf vertrauen, dass ihre AIInfrastrukturbereitstellung schnell und reibungslos verläuft.
Für Großkunden mit anspruchsvollen AI-Inferenzanforderungen definiert das Referenzdesign der NVIDIA AI Data Platform, das mit Pure Storage® FlashBlade//EXA™ und Portworx® implementiert wurde, neu, wie Unternehmen riesige Datenmengen in Echtzeitintelligenz umwandeln können. Dieser umfassende Stack beschleunigt nicht nur die Inferenz, sondern ermöglicht präzise Argumentation im großen Maßstab, sodass große Unternehmen komplexe Datensätze mit chirurgischer Genauigkeit dekodieren und gleichzeitig die Sicherheit der Produktionsklasse erhalten können.
Die Intelligenz-Imperative: Warum Geschwindigkeit und Präzision wichtig sind
Moderne Unternehmen arbeiten in Umgebungen, in denen verzögerte Erkenntnisse mit verpassten Gelegenheiten gleichzusetzen sind. Eine Pure Storage-Implementierung der NVIDIA AI-Datenplattform behebt dies, indem sie beschleunigtes Computing mit intelligenter Datenorchestrierung kombiniert und eine Feedbackschleife zwischen Unternehmenswissen und AIBegründung schafft. Im Kern ermöglicht diese Infrastruktur:
- Echtzeitanalyse von multimodalen Daten (Text, Bilder, Video) mit Latenzzeit in weniger als Sekunden
- Kontextbewusste Argumentation über verteilte Datensätze hinweg
- Vertrauenswürdige Erkenntnisse und Daten-Governance durch granulare Sicherheitskontrollen
Durch die Nutzung beschleunigter Rechenleistung durch NVIDIA Blackwell, NVIDIA-Netzwerke, RAG-Software (Retrieval-augmented Generation), einschließlich NVIDIA NeMo Retriever-Microservices und dem AI-Q-NVIDIA-Blueprint, sowie die Metadaten-optimierte Architektur von Pure Storage verkürzen Unternehmen die Zeit bis zum Einblick von Tagen auf Sekunden und behalten gleichzeitig eine sehr hohe Inferenzgenauigkeit in Produktionsumgebungen bei.
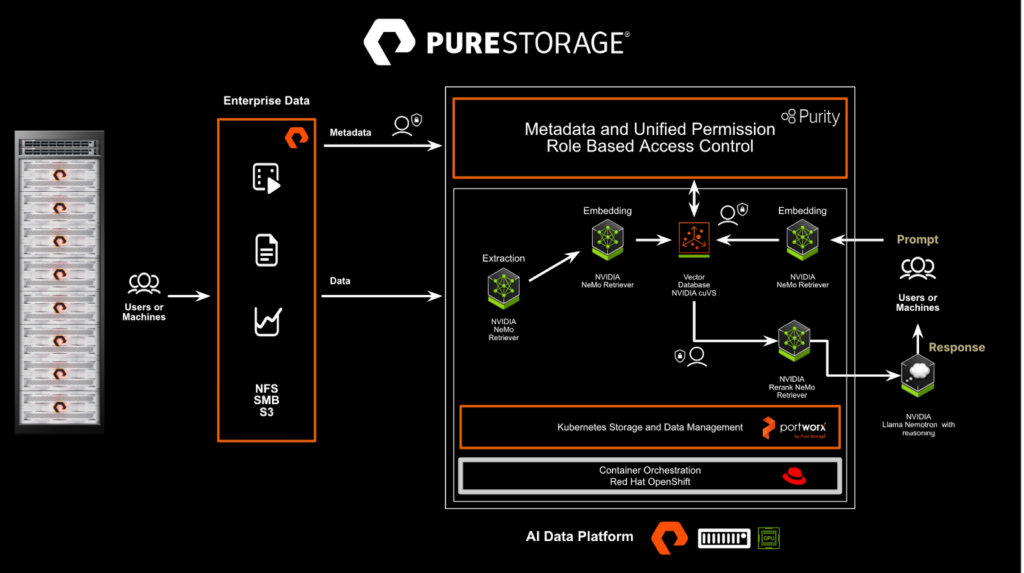
Abbildung 1. Pure Storage-Implementierung der NVIDIA AI-Datenplattform.
FlashBlade//EXA: Die Data Velocity Engine
Pure Storage FlashBlade//EXA zerbricht herkömmliche Storage-Engpässe mit einer Durchsatzleistung von mehr als 10 TB/s in einem einzigen Namespace – genug, um die gesamte Sammlung der Library of Congress in weniger als drei Minuten zu verarbeiten.
So ermöglicht die Disaggregation von Daten und Metadata massive Inferenz im großen Maßstab
Der Hauptvorteil des disaggregierten Designs von FlashBlade//EXA ist die Fähigkeit, Metadaten und Datenleistung unabhängig voneinander zu skalieren. Das bedeutet, dass Unternehmen ihre Storage-Architektur genau an die spezifischen Anforderungen ihrer Inferenz-Workloads anpassen können, ohne eine der Komponenten überprovisionieren zu müssen.
Bei Inferenz-Workloads, die schnellen Zugriff auf Tausende oder Millionen kleinerer Dateien erfordern, kann die Metadaten entsprechend skaliert werden. Ähnlich kann bei Workloads, die mit massiven Datensätzen aus riesigen Dateien zu tun haben, die Datenschicht ohne unnötigen Metadaten-Overhead erweitert werden. Diese Flexibilität ermöglicht eine nahezu unbegrenzte Skalierbarkeit.
Die Trennung von Metadaten und Datenverarbeitung ermöglicht einen nicht blockierenden Datenzugriff, der in Hochleistungs-Computing-Szenarien, in denen Metadaten tatsächlichen Daten-I/O-Operationen entsprechen oder sogar übertreffen können, immer wertvoller wird. Diese Architektur stellt sicher, dass GPUs konsistent mit Daten zu den höchstmöglichen Raten versorgt werden, wodurch kostspielige Leerlaufzeiten vermieden werden.
Mit seiner disaggregierten, massiv parallelen Architektur löst FlashBlade//EXA das Problem, AI-Workloads zu skalieren, wodurch ungenutzte GPU-Zeit entfällt, sodass Unternehmen AITraining und -Inferenz beschleunigen können. Diese effiziente Datenbereitstellung ist entscheidend für Inferenz-Workloads, bei denen eine konsistente, vorhersehbare Performance oft wichtiger ist als Spitzengeschwindigkeiten, was durch effizientes KV-Cache-Sharing für platzende und gemischte Workloads ermöglicht wird.
Die Portworx- und FlashBlade//EXA-Synergie zur Inferenzbeschleunigung
Die Synergie zwischen Portworx und FlashBlade//EXA beschleunigt die AI-Inferenz in großem Maßstab, indem sie das native Datenmanagement von Portworx Kubernetes und intelligentes Modell-Caching mit der ultraschnellen, massiv parallelen FlashBlade//EXA-Storage-Architektur kombiniert. Portworx sorgt für Hochverfügbarkeit, Zugriff mit geringer Latenz und nahtlose Skalierung von Modelldaten über verteilte Inferenz-Workloads hinweg, während FlashBlade//EXA Storage- und Metadaten mit außergewöhnlichem Durchsatz und disaggregierter Skalierung beseitigt. Zusammen maximieren sie die GPU-Auslastung, minimieren die Inferenzlatenz und bilden eine robuste, flexible Grundlage für die Bereitstellung und Verwaltung von AI-Inferenzpipelines in Produktionsumgebungen.
Die Disaggregierte KV-Cache-Revolution: Präzision im großen Maßstab
Die KV-Cache-Architektur von NVIDIA interpretiert Inferenzpipelines durch drei Innovationen neu:
- Nahezu-GPU-Präfix-Caching
- Speichert gängige Abfragemuster (z. B. Überprüfungen der Einhaltung gesetzlicher Vorschriften) direkt in GPU-angrenzendem NVMe
- Load-Aware-Planung
- Ordnet Vorab-/Decodierungsressourcen dynamisch basierend auf der Komplexität der Abfrage zu
- Aufrechterhaltung einer GPU-Auslastung von 95 % auch bei Traffic-Spitzen
- Heterogenes GPU-Pooling
- Ermöglicht Cluster mit gemischten GPU-Varianten zum Teilen von KV-Cache-Speicher
Diese Pure Storage-Lösung ergänzt das Vorstehende mit den folgenden Funktionen, um eine durchgängige Beschleunigung der Token-pro-Sekunde-Performance für umfangreiche AI-Inferenzimplementierungen zu ermöglichen.
- KV-Cache-Sharing: Gewährleistet einen effizienten KV-Cache-Sharing unter der exponentiell multiplizierenden Herde.
- Hohe I/O-Konkurrenz: Die hochgradig gleichzeitige Architektur von FlashBlade® ist nicht nur ultraschnell, sondern zeichnet sich auch durch dieses exponentiell gleichzeitige I/O-Muster aus.
- Datenreduktion: Die automatische Komprimierung des KV-Cache bedeutet schnellere I/O und kürzere Vorfüllzeiten.
Sicherheit als Enabler: RBAC für zuverlässige Erkenntnisse in RAG und Agentischer AI
Die Implementierung eines RBAC-Frameworks (Rolle-Based Access Control) innerhalb einer abruffähigen Generation (RAG) oder einer agentischen Pipeline ist für eine sichere und effiziente Datenverarbeitung von entscheidender Bedeutung. Dazu gehört die Einrichtung einer einheitlichen Berechtigungsebene zum Definieren von Benutzerrollen und deren Zugriffsrechten über verschiedene Phasen hinweg: Datenaufnahme, Abruf, Verarbeitung und Storage. Darüber hinaus müssen die Komponenten ein effizientes Abfrageverständnis unterstützen, um den Datenzugriff auf der Grundlage von Benutzerrollen und -absichten anzupassen und die Einhaltung festgelegter Berechtigungen sicherzustellen. Die AIErweiterungs- und Generierungsprozesse müssen kontextspezifische Daten in generative Modelle integrieren und dabei Sicherheits- und Zugriffsprotokolle beibehalten. Effektive Prüf- und Überwachungsmechanismen sind entscheidend für die Verfolgung von Zugriffsmustern und die Sicherstellung der Einhaltung von RBAC-Regeln, was die allgemeine Sicherheit erhöht. Best Practices für die Sicherheit, z. B. die Verwendung eines Zero-Trust-Modells und JWT-basierter Authentifizierung, betonen vorübergehende und sichere Zugriffskontrollen und minimieren gleichzeitig die Performance-Einbußen in der Pipeline.
Portworx implementiert ein Zero-Trust-Sicherheitsmodell, das den Datenzugriff beschleunigt und nicht behindert:
- StorageClass granulare Verschlüsselung: Verschlüsselt sensible personenbezogene Daten während des Fluges und im Ruhezustand und hält gleichzeitig die Trainingsdaten zugänglich
- JWT-basierte Zugriffskontrolle: Gewährt vorübergehenden, kontextbewussten Zugriff auf RAG-Pipelines
- Audit-konforme Protokollierung: Verfolgt die Datenlinie von der Rohaufnahme bis zur Inferenzausgabe
NVIDIA AI-Q: Die begründende Intelligence-Ebene
Der AI-Q NVIDIA Blueprint verwandelt statische Daten in dynamisches Wissen durch drei Kernkomponenten:
- Multimodale Extraktionsengines: Konvertiert PDF-Schemas, Servicehandbücher und Anruftranskripte in strukturierte Wissensdiagramme
- NeMo Retriever Microservices: Bietet extrem hohe Rückrufgenauigkeit bei Vektorsuchen im Milliardenmaßstab
- Orchestrierung des NVIDIA Agent Intelligence-Toolkits: Profiling und Optimierung für komplexe agentische Systeme
In Kombination mit der Datengeschwindigkeit von FlashBlade//EXA ermöglicht dieser Stack das, was wir als „Präzisionsbegründung“ bezeichnen: die Fähigkeit, aus Rohdaten in sehr wenigen Abfragezyklen Boardroom-fähige Erkenntnisse abzuleiten.
Power Precision Reasoning in großem Maßstab: Der neue Wettbewerbsvorteil
Unternehmen, die diesen Stack einführen, berichten transformative Ergebnisse.
Eine Pure Storage-Implementierung der NVIDIA AI-Datenplattform bietet die ultimative Argumentationsdichte – die Möglichkeit, verwertbare Erkenntnisse pro verarbeitetem Terabyte zu gewinnen. Durch die Kombination von beschleunigtem Computing mit NVIDIA Blackwell und der Datenverfügbarkeit von Pure Storage erreichen Unternehmen das, was bisher undenkbar war: die Verwandlung ihres gesamten Datenbestands in ein strategisches Argument.
Fazit: Intelligenz im Geschäftstempo
Die Zusammenarbeit zwischen Pure Storage und NVIDIA stellt mehr als nur eine extrem skalierbare AI-Infrastruktur dar – unsere lange Geschichte der Zusammenarbeit stellt sicher, dass Kunden jeder Größe und AIReife unterstützt werden können, unabhängig davon, ob sie gerade mit FlashBlade//S oder AIRI® beginnen oder auf das höchste Niveau an AI– und HPC-Anforderungen skalieren.
Während AI vom experimentellen Projekt zum Hauptumsatztreiber übergeht, bildet diese Plattform die Grundlage für kontinuierliche Intelligenz – die Fähigkeit, mit maschineller Präzision zu denken, zu entscheiden und auf Live-Datenströme zu reagieren. Die Zukunft gehört Unternehmen, die nicht nur Daten speichern, sondern sie auch so schnell verstehen, wie sie denken.
Mehr erfahren:
FlashBlade//EXA für KI AI und HPC im extremen Maßstab

FlashBlade//EXA
Experience the World’s Most Powerful Data Storage Platform for AI
Power AI’s Next Frontier
Learn more about the most powerful data storage platform ever, built for AI.



